Module fusus.convert
Convenience methods to call conversions to and from tsv and to tf.
The pipeline can read Arabic books in the form of page images, and returns structured data in the form of a tab separated file (TSV).
The PDF text extraction of the Lakhnawi file also produces a TSV file.
Both kinds of TSV files can be converted furhter into Text-Fabric.
Input
See fusus.works for how to specify the input for fusus operations.
TSV output
The TSV data from both the pipeline and the text extraction is one word per line.
Fields are integer valued, except for fields with names ending in $.
The fields of the pipeline results (P) are roughly the same as those of the
text extraction results (T):
(P) page stripe block$ line left top right bottom confidence letters punc$
(T) page line column span direction$ left top right bottom letters punc$
Divisions (P)
Each page is divided into stripe. Stripes are horizontal regions from the left edge to the right edge of the page/
Each stripe is divided into blocks. Blocks are vertical parts inside a stripe, with a stroke in between. If there is no stroke, there is only one block in the stripe. There are at most two blocks in a stripe.
Each block is divided into lines.
See also fusus.layout.
Each line is divided into words.
Divisions (T)
Each page is divided into lines.
Each line is divided into columns
(in case of hemistic verses, see Lakhnawi.columns).
Each column is divided into spans. Span transitions occur precisely there where changes in writing direction occur.
Each span is divided into words.
Fields (TP)
Each word occupies exactly one line in the TSV file, with the following fields:
(TP)page page number( P)stripe stripe number within the page( P)block (empty string orrorl)( P)line line number within the block(T )line line number within the page(T )column column number within the line(T )span span number within the column(T )direction (lorr) writing direction of the span(TP)left x coordinate of left boundary(TP)top y coordinate of top boundary(TP)right x coordinate of right boundary(TP)bottom y coordinate of bottom boundary( P)confidence measure of OCR confidence (0 .. 100) percent(TP)letters letters of the word (possibly the empty string)(TP)punc non-letters after the word
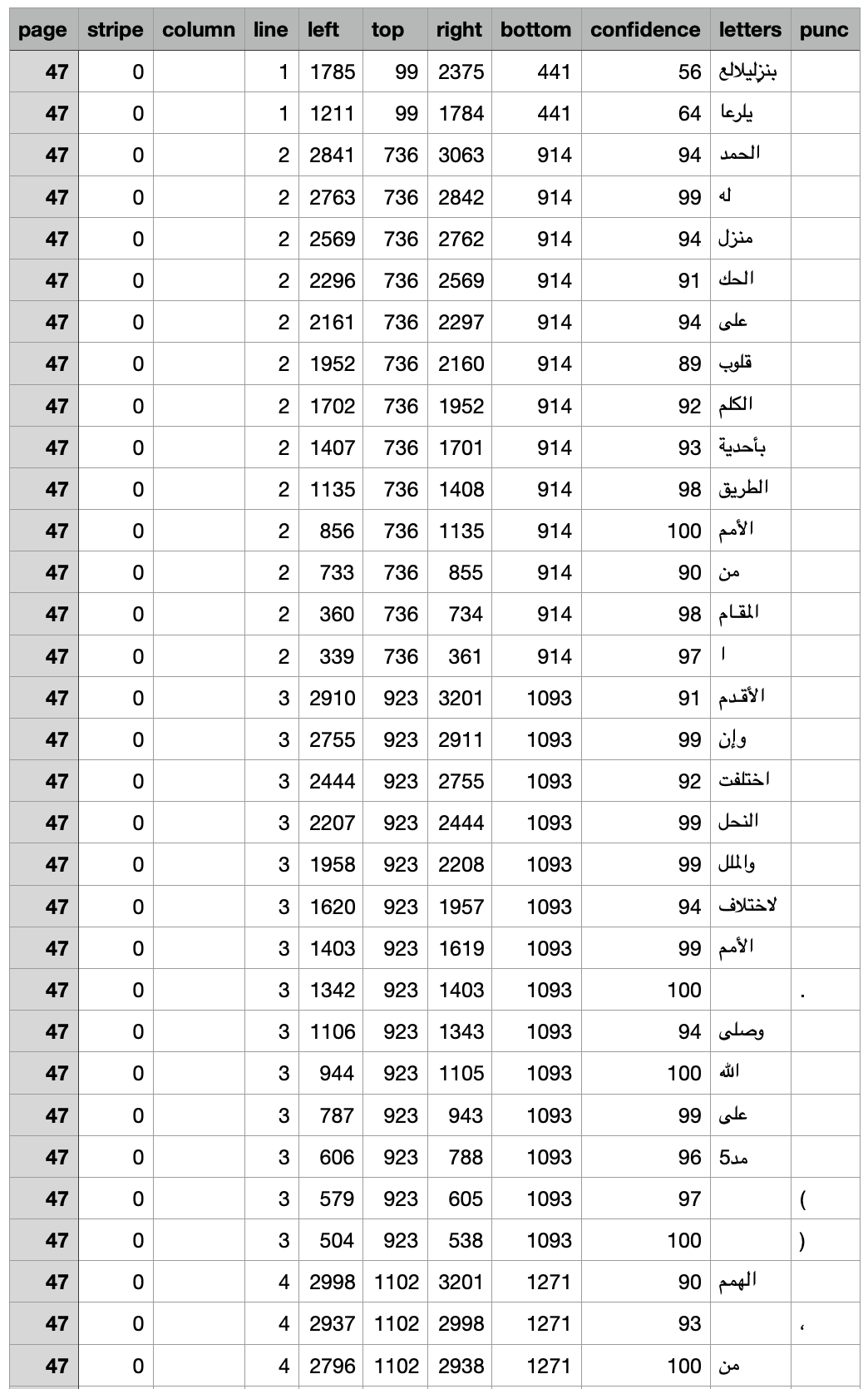
Example (P)
The start of the Afifi TSV:
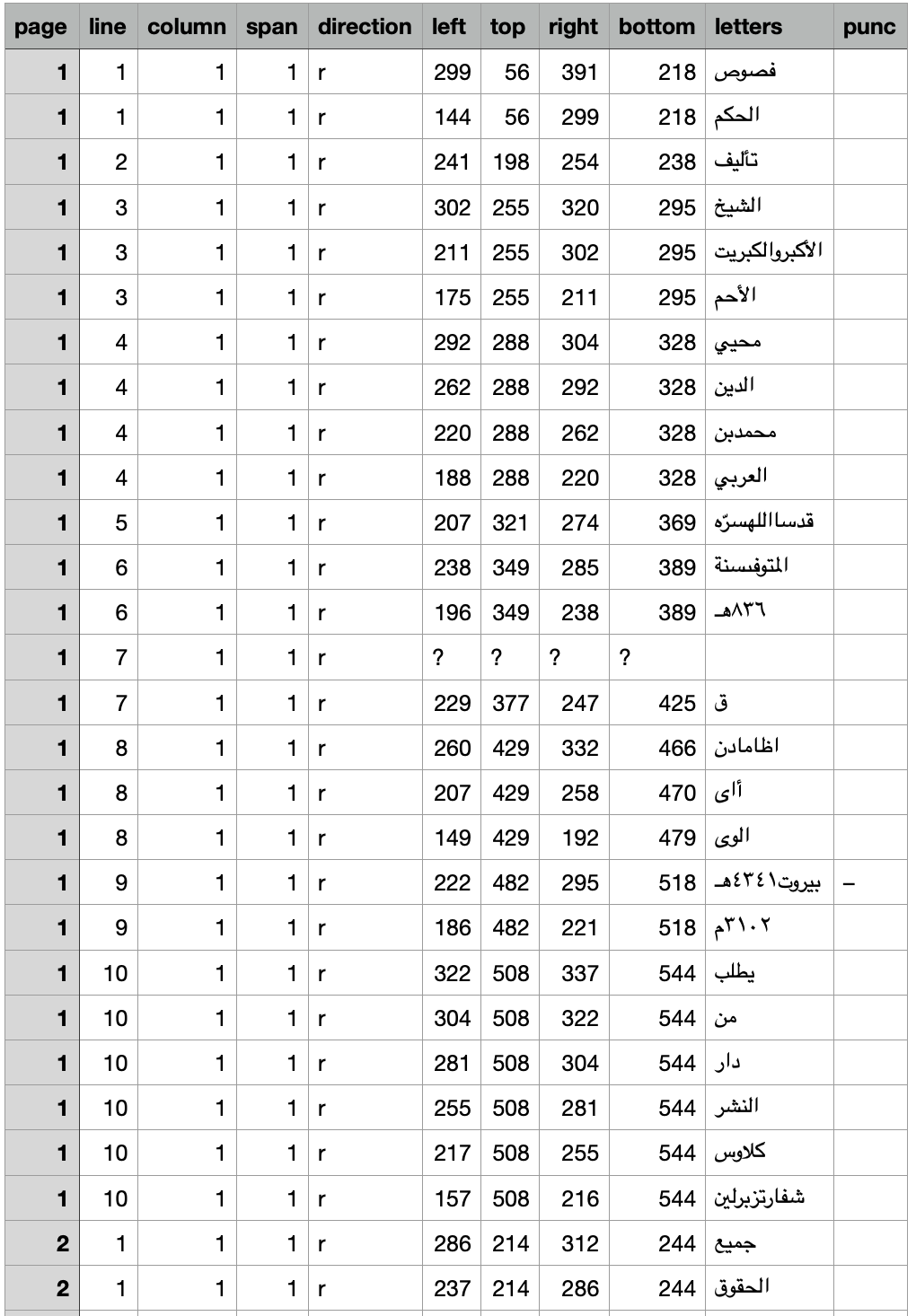
Example (T)
The start of the Lakhnawi TSV:
Run
You can run the pipeline on the known works inside the ur directory in this repo or on books that you provide yourself.
This script supports one-liners on the command line to execute the pipeline and various conversion processes.
See
HELP.
Here are concrete commands for known works:
python3 -m fusus.convert tsv fususa
python3 -m fusus.convert tsv fususl
This will run the OCR pipeline for the Afifi/Lakhnawi editions respectively, and deliver TSV data as result;
python3 -m fusus.convert tf fususa 0.5
python3 -m fusus.convert tf fususl 0.5
python3 -m fusus.convert tf fusus 0.5
This will convert the TSV data to TF and deliver the tf files in version 0.5,
for the Afifi (fususa) and Lakhnawi (fusul) editions or for the
combined work (fusus).
In order to combine fususa and fususl run the combine task, see below.
python3 -m fusus.convert tf fususa 0.5 loadonly
python3 -m fusus.convert tf fususl 0.5 loadonly
python3 -m fusus.convert tf fusus 0.5 loadonly
This will load the TF data in version 0.5. The first time it loads, some extra computations will be performed, and a binary version of the tf files will be generated, which will be used for subsequent use by Text-Fabric.
python3 -m fusus.convert combine fusus 0.5
This will combine the data of fususl and fususl (both version 0.5), into a tsv file called fusus, with version 0.5
Load TSV
The function loadTsv() to load TSV data in memory.
For known works, it will also convert the data types of the appropriate fields
to integer.
Expand source code Browse git
"""Convenience methods to call conversions to and from tsv and to tf.
The pipeline can read Arabic books in the form of page images,
and returns structured data in the form of a tab separated file (TSV).
The PDF text extraction of the Lakhnawi file also produces a TSV file.
Both kinds of TSV files can be converted furhter into Text-Fabric.
## Input
See `fusus.works` for how to specify the input for *fusus* operations.
## TSV output
The TSV data from both the pipeline and the text extraction is one word per line.
Fields are integer valued, except for fields with names ending in $.
The fields of the pipeline results `(P)` are roughly the same as those of the
text extraction results `(T)`:
```
(P) page stripe block$ line left top right bottom confidence letters punc$
(T) page line column span direction$ left top right bottom letters punc$
```
### Divisions `(P)`
Each *page* is divided into *stripe*.
Stripes are horizontal regions from the left edge to the right edge of the page/
Each *stripe* is divided into *blocks*.
Blocks are vertical parts inside a stripe, with a stroke in between.
If there is no stroke, there is only one block in the stripe.
There are at most two blocks in a stripe.
Each *block* is divided into *lines*.
See also `fusus.layout`.
Each line is divided into *words*.
### Divisions `(T)`
Each *page* is divided into *lines*.
Each *line* is divided into *columns*
(in case of hemistic verses, see `Lakhnawi.columns`).
Each *column* is divided into *spans*.
Span transitions occur precisely there where changes in writing direction occur.
Each *span* is divided into *words*.
### Fields `(TP)`
Each word occupies exactly one line in the TSV file, with the following fields:
* `(TP)` **page** page number
* `( P)` **stripe** stripe number within the page
* `( P)` **block** (empty string or `r` or `l`)
* `( P)` **line** line number within the block
* `(T )` **line** line number within the page
* `(T )` **column** column number within the line
* `(T )` **span** span number within the column
* `(T )` **direction** (`l` or `r`) writing direction of the span
* `(TP)` **left** *x* coordinate of left boundary
* `(TP)` **top** *y* coordinate of top boundary
* `(TP)` **right** *x* coordinate of right boundary
* `(TP)` **bottom** *y* coordinate of bottom boundary
* `( P)` **confidence** measure of OCR confidence (0 .. 100) percent
* `(TP)` **letters** letters of the word (possibly the empty string)
* `(TP)` **punc** non-letters after the word
### Example `(P)`
The start of the Afifi TSV:

### Example `(T)`
The start of the Lakhnawi TSV:

## Run
You can run the pipeline on the known works inside the *ur* directory in this repo or
on books that you provide yourself.
This script supports one-liners on the command line
to execute the pipeline and various conversion processes.
See `fusus.convert.HELP`.
Here are concrete commands for known works:
---
``` sh
python3 -m fusus.convert tsv fususa
python3 -m fusus.convert tsv fususl
```
This will run the OCR pipeline for the Afifi/Lakhnawi editions respectively,
and deliver TSV data as result;
---
``` sh
python3 -m fusus.convert tf fususa 0.5
python3 -m fusus.convert tf fususl 0.5
python3 -m fusus.convert tf fusus 0.5
```
This will convert the TSV data to TF and deliver the tf files in version 0.5,
for the Afifi (fususa) and Lakhnawi (fusul) editions or for the
combined work (fusus).
In order to combine fususa and fususl run the `combine` task, see below.
---
``` sh
python3 -m fusus.convert tf fususa 0.5 loadonly
python3 -m fusus.convert tf fususl 0.5 loadonly
python3 -m fusus.convert tf fusus 0.5 loadonly
```
This will load the TF data in version 0.5.
The first time it loads, some extra computations will be performed, and
a binary version of the tf files will be generated, which will be used for
subsequent use by Text-Fabric.
---
``` sh
python3 -m fusus.convert combine fusus 0.5
```
This will combine the data of fususl and fususl (both version 0.5),
into a tsv file called fusus, with version 0.5
---
## Load TSV
The function `loadTsv` to load TSV data in memory.
For known works, it will also convert the data types of the appropriate fields
to integer.
"""
import sys
import re
from tf.core.helpers import unexpanduser
from .works import getFile, getWorkDir, getTfDest, WORKS
from .lib import parseNums
from .book import Book
from .lakhnawi import Lakhnawi
from .tfFromTsv import convert, loadTf
from .align import Alignment
__pdoc__ = {}
HELP = """
Convert tsv data files to TF and optionally loads the TF.
python3 -m fusus.convert --help
python3 -m fusus.convert tsv source ocr|noocr pages
python3 -m fusus.convert combine source ocr|noocr pages
python3 -m fusus.convert tf source ocr|noocr pages versiontf [load] [loadonly]
--help: print this text and exit
source : a work (given as keyword or as path to its work directory)
Examples:
fususl (Fusus Al Hikam in Lakhnawi edition)
fususa (Fusus Al Hikam in Afifi edition)
fusus (combination of fususl and fususa)
any commentary by its keyword
~/github/myorg/myrepo/mydata
mydir/mysubdir
NB: when `fusus` is passed, it is the destination,
and the sources are fususa and fususl.
pages : page specification, only process these pages; default: all pages
Examples:
50
50,70
50-70,91,92,300-350
ocr : assume the work is in the OCR pipeline
noocr : assume the work is not in the OCR pipeline
(it is then a text extract from a pdf)
For tf only:
versiontf : loads the generated TF; if missing this step is not performed
Examples:
0.4
3.7.2
load : loads the generated TF; if missing this step is not performed
loadOnly : does not generate TF; loads previously generated TF
"""
"""Help"""
__pdoc__["HELP"] = f"``` text\n{HELP}\n```"
def makeTf(
versionTf=None,
source=None,
ocred=None,
pages=None,
load=False,
loadOnly=False,
):
"""Make Text-Fabric data out of the TSV data of a work.
The work is specified either by the name of a known work
(e.g. `fususa`, `fususl`)
or by specifying the work directory.
The function needs to know whether the tsv comes out of an OCR process or
from the text extraction of a PDF.
In case of a known work, this is known and does not have to be specified.
Otherwise you have to pass it.
Parameters
----------
versionTf: string
A version number for the TF to be generated, e.g. `0.3`.
Have a look in the fusus tf subdirectory, and see which version already exists,
and then choose a higher version if you do not want to overwrite the existing
version.
source: string, optional `None`
The key of a known work, see `fusus.works.WORKS`.
Or else the path to directory of the work.
ocred: string
Whether the tsv is made by the OCR pipeline.
Not needed in case of a known work.
pages: string|int, optional `None`
A specification of zero or more page numbers (see `fusus.lib.parseNums`).
Only rows belonging to selected pages will be extracted.
If None, all pages will be taken.
load: boolean, optional `False`
If TF generation has succeeded, load the tf files for the first time.
This will trigger a one-time precomputation step.
loadOnly: boolean, optional `False`
Skip TF generation, assume the TF is already in place, and load it.
This might trigger a one-time precomputation step.
Returns
-------
nothing
It will run the appripriate pipeline and generate tf in the appropriate
locations.
"""
doLoad = load or loadOnly
doConvert = not loadOnly
print("TSV to TF converter for the Fusus project")
print(f"TF target version = {versionTf}")
good = True
print(f"===== SOURCE {source} =====")
if doConvert:
if not convert(source, ocred, pages, versionTf):
good = False
if good:
if doLoad:
dest = getTfDest(source, versionTf)
if dest is None:
good = False
else:
loadTf(dest)
return good
def makeTsv(source=None, ocred=None, pages=None):
"""Make TSV data out of the source of a work.
The work is specified either by the name of a known work
(e.g. `fususa`, `fususl`)
or by specifying the work directory.
The function needs to know whether the tsv comes out of an OCR process or
from the text extraction of a PDF.
In case of a known work, this is known and does not have to be specified.
Otherwise you have to pass it.
Parameters
----------
source: string, optional `None`
The key of a known work, see `fusus.works.WORKS`.
Or the path to directory of the work.
ocred: string
Whether the tsv is made by the OCR pipeline.
Not needed in case of a known work.
pages: string|int, optional `None`
A specification of zero or more page numbers (see `fusus.lib.parseNums`).
Only rows belonging to selected pages will be extracted.
If None, all pages will be taken.
Returns
-------
nothing
It will run the appropriate pipeline and generate tsv in the appropriate
locations.
"""
(workDir, ocred) = getWorkDir(source, ocred)
if workDir is None:
return
ocrRep = "with OCR" if ocred else "no OCR"
print(f"Making TSV data from {unexpanduser(workDir)} ({ocrRep})")
if ocred:
B = Book(cd=workDir)
B.process(pages=pages)
B.exportTsv(pages=pages)
else:
Lw = Lakhnawi()
print("Reading PDF")
Lw.getPages(pages)
print("\nExporting TSV")
Lw.tsvPages(pages)
print("Closing")
Lw.close()
def combineTsv(versionTf=None, source=None, ocred=None, pages=None):
CASES = {
3072: (5, 1),
4597: (1, 1),
4598: (1, 1),
4600: (0, 4),
8273: (4, 0),
13539: (2, 1),
14878: (1, 1),
14879: (1, 0),
14880: (12, 0),
16198: (1, 1),
16199: (1, 1),
16200: (1, 1),
16201: (1, 1),
16212: (1, 1),
18029: (6, 1),
22762: (1, 0),
22763: (1, 1),
22764: (1, 1),
}
print(f"Aligning LK with AF for version {versionTf}")
ALIGN = Alignment()
ALIGN.readEditions(versionTf, CASES)
ALIGN.doDiffs()
print("Merging AF into LK")
alignment = ALIGN.alignment
(headLK, rowsLK) = loadTsv("fususl", raw=True)
(headAF, rowsAF) = loadTsv("fususa", raw=True)
rowIndexLK = {i + 1: row for (i, row) in enumerate(rowsLK)}
rowIndexAF = {i + 1: row for (i, row) in enumerate(rowsAF)}
head = "\t".join((
*headLK[0:5],
*headLK[9:11],
*headLK[12:],
"slot_lk",
"combine_lk",
"editdistance",
"ratio",
"combine_af",
"slot_af",
f"{headAF[0]}_af",
f"{headAF[3]}_af",
*(f"{h}_af" for h in headAF[9:]),
))
prevLocLK = ("0", "0", "0", "0", "r")
prevLocAF = ("0", "0")
emptyRestLK = ("", "", "", "", "", "", "", "", "", "")
emptyRestAF = ("", "", "")
(destFile, ocred) = getFile("fusus", False)
if not destFile:
return False
print(f"Writing result to {destFile}")
with open(destFile, "w") as fh:
fh.write(f"{head}\n")
for (iLK, left, d, r, right, iAF) in alignment:
if iLK:
row = rowIndexLK[iLK]
prevLocLK = tuple(row[0:5])
rowLK = (*prevLocLK, *row[9:11], *row[12:])
else:
rowLK = (*prevLocLK, *emptyRestLK)
if iAF:
row = rowIndexAF[iAF]
prevLocAF = (row[0], row[3])
rowAF = (*prevLocAF, *row[9:])
else:
rowAF = (*prevLocAF, *emptyRestAF)
row = "\t".join(
(
*rowLK,
str(iLK),
str(left),
str(d),
f"{r:3.1f}",
str(right),
str(iAF),
*rowAF,
)
)
fh.write(f"{row}\n")
def loadTsv(source=None, ocred=None, pages=None, raw=False):
"""Load a tsv file into memory.
The tsv file either comes from a known work or is specified by a path.
If it comes from a known work, you only have to pass the key of that work,
e.g. `fususa`, or `fususl`.
The function needs to know whether the tsv comes out of an OCR process or
from the text extraction of a PDF.
In case of a known work, this is known and does not have to be specified.
Otherwise you have to pass it.
!!! caution "word-based"
This function can load the word-based TSV files, not the character based ones.
Parameters
----------
source: string, optional `None`
The key of a known work, see `fusus.works.WORKS`.
Or the path to the tsv file.
raw: boolean, optional False
If True, the lines are split into fields, but no type conversion is done
ocred: string
Whether the tsv file comes from the OCR pipeline.
Not needed in case of a known work.
pages: string|int, optional `None`
A specification of zero or more page numbers (see `fusus.lib.parseNums`).
Only rows belonging to selected pages will be extracted.
If None, all pages will be taken.
Returns
-------
tuple
Two members:
* head: a tuple of field names
* rows: a tuple of data rows, where each row is a tuple of its fields
"""
(sourceFile, ocred) = getFile(source, ocred)
if sourceFile is None:
return ((), ())
sep = WORKS[source].get("sep", "\t")
pageNums = parseNums(pages)
data = []
print(f"Loading TSV data from {unexpanduser(sourceFile)}")
with open(sourceFile) as fh:
head = tuple(next(fh).rstrip("\n").split(sep))
for line in fh:
row = tuple(line.rstrip("\n").split(sep))
if not raw:
page = int(row[0])
if pageNums is not None and page not in pages:
continue
if ocred:
row = (
page,
int(row[1]),
row[2],
int(row[3]),
*(None if c == "?" else int(c) for c in row[4:8]),
int(row[8]),
*row[9:11],
)
else:
row = (
page,
*(int(c) for c in row[1:4]),
row[4],
*(None if c == "?" else int(c) for c in row[5:9]),
*row[9:11],
)
data.append(row)
return (head, tuple(data))
# MAIN
def parseArgs(args):
"""Parse arguments from the command line.
Performs sanity checks.
Parameters
----------
args: list
All command line arguments.
The full command is stripped from what `sys.argv` yields.
Returns
-------
passed: dict
The interpreted values of the command line arguments,
which will be passed on to the rest of program.
"""
passed = dict(
command=None,
source=None,
ocred=None,
pages=None,
load=None,
loadOnly=None,
versionTf=None,
)
good = True
NUMS = re.compile(r"^[0-9][0-9,-]*$")
def setArg(name, value):
nonlocal good
if passed[name] is None:
passed[name] = value
else:
print(f"Repeated: `{value}` for {name}")
good = False
for arg in args:
if arg in {"tf", "tsv", "combine"}:
setArg("command", arg)
elif arg == "load":
setArg("load", True)
elif arg == "loadonly":
setArg("loadOnly", True)
elif arg == "ocr":
setArg("ocred", True)
elif arg == "noocr":
setArg("ocred", False)
elif "." in arg:
setArg("versionTf", arg)
elif NUMS.match(arg):
setArg("pages", arg)
elif arg == "--help":
print(HELP)
good = None
else:
setArg("source", arg)
if good:
if passed["command"] is None:
print("No command specified (tf or tsv or combine)")
good = False
if passed["source"] is None:
if passed["command"] == "combine":
print("No destination specfified (fusus)")
else:
print(
"No source specified "
"(fususl, fususa, commentary_name, directory_path)"
)
good = False
if passed["command"] == "combine":
if passed["versionTf"] is None:
print("No TSV version specified (e.g. 0.3)")
good = False
if passed["command"] == "tf":
if passed["versionTf"] is None:
print("No TF version specified (e.g. 0.3)")
good = False
if passed["load"] is None:
passed["load"] = False
if passed["loadOnly"] is None:
passed["loadOnly"] = False
else:
for name in ("load", "loadOnly"):
if passed[name] is not None:
print(f"Illegal argument `{passed[name]}` for {name}")
good = False
del passed[name]
print(f"{good=} {passed=}")
return (good, passed)
def main():
"""Perform tasks.
See `HELP`.
"""
args = () if len(sys.argv) == 1 else tuple(sys.argv[1:])
(good, passed) = parseArgs(args)
if not good:
return good is None
kwargs = {k: v for (k, v) in passed.items() if k != "command"}
if passed["command"] == "tsv":
print("TSV to TF converter for the Fusus project")
return makeTsv(**kwargs)
elif passed["command"] == "combine":
print("TSV combiner of fususa and fususl")
return combineTsv(**kwargs)
elif passed["command"] == "tf":
print(f"TF target version = {passed['versionTf']}")
return makeTf(**kwargs)
if __name__ == "__main__":
sys.exit(0 if main() else 1)Global variables
var HELP-
Convert tsv data files to TF and optionally loads the TF. python3 -m fusus.convert --help python3 -m fusus.convert tsv source ocr|noocr pages python3 -m fusus.convert combine source ocr|noocr pages python3 -m fusus.convert tf source ocr|noocr pages versiontf [load] [loadonly] --help: print this text and exit source : a work (given as keyword or as path to its work directory) Examples: fususl (Fusus Al Hikam in Lakhnawi edition) fususa (Fusus Al Hikam in Afifi edition) fusus (combination of fususl and fususa) any commentary by its keyword ~/github/myorg/myrepo/mydata mydir/mysubdir NB: when `fusus` is passed, it is the destination, and the sources are fususa and fususl. pages : page specification, only process these pages; default: all pages Examples: 50 50,70 50-70,91,92,300-350 ocr : assume the work is in the OCR pipeline noocr : assume the work is not in the OCR pipeline (it is then a text extract from a pdf) For tf only: versiontf : loads the generated TF; if missing this step is not performed Examples: 0.4 3.7.2 load : loads the generated TF; if missing this step is not performed loadOnly : does not generate TF; loads previously generated TF
Functions
def combineTsv(versionTf=None, source=None, ocred=None, pages=None)-
Expand source code Browse git
def combineTsv(versionTf=None, source=None, ocred=None, pages=None): CASES = { 3072: (5, 1), 4597: (1, 1), 4598: (1, 1), 4600: (0, 4), 8273: (4, 0), 13539: (2, 1), 14878: (1, 1), 14879: (1, 0), 14880: (12, 0), 16198: (1, 1), 16199: (1, 1), 16200: (1, 1), 16201: (1, 1), 16212: (1, 1), 18029: (6, 1), 22762: (1, 0), 22763: (1, 1), 22764: (1, 1), } print(f"Aligning LK with AF for version {versionTf}") ALIGN = Alignment() ALIGN.readEditions(versionTf, CASES) ALIGN.doDiffs() print("Merging AF into LK") alignment = ALIGN.alignment (headLK, rowsLK) = loadTsv("fususl", raw=True) (headAF, rowsAF) = loadTsv("fususa", raw=True) rowIndexLK = {i + 1: row for (i, row) in enumerate(rowsLK)} rowIndexAF = {i + 1: row for (i, row) in enumerate(rowsAF)} head = "\t".join(( *headLK[0:5], *headLK[9:11], *headLK[12:], "slot_lk", "combine_lk", "editdistance", "ratio", "combine_af", "slot_af", f"{headAF[0]}_af", f"{headAF[3]}_af", *(f"{h}_af" for h in headAF[9:]), )) prevLocLK = ("0", "0", "0", "0", "r") prevLocAF = ("0", "0") emptyRestLK = ("", "", "", "", "", "", "", "", "", "") emptyRestAF = ("", "", "") (destFile, ocred) = getFile("fusus", False) if not destFile: return False print(f"Writing result to {destFile}") with open(destFile, "w") as fh: fh.write(f"{head}\n") for (iLK, left, d, r, right, iAF) in alignment: if iLK: row = rowIndexLK[iLK] prevLocLK = tuple(row[0:5]) rowLK = (*prevLocLK, *row[9:11], *row[12:]) else: rowLK = (*prevLocLK, *emptyRestLK) if iAF: row = rowIndexAF[iAF] prevLocAF = (row[0], row[3]) rowAF = (*prevLocAF, *row[9:]) else: rowAF = (*prevLocAF, *emptyRestAF) row = "\t".join( ( *rowLK, str(iLK), str(left), str(d), f"{r:3.1f}", str(right), str(iAF), *rowAF, ) ) fh.write(f"{row}\n") def loadTsv(source=None, ocred=None, pages=None, raw=False)-
Load a tsv file into memory.
The tsv file either comes from a known work or is specified by a path.
If it comes from a known work, you only have to pass the key of that work, e.g.
fususa, orfususl.The function needs to know whether the tsv comes out of an OCR process or from the text extraction of a PDF.
In case of a known work, this is known and does not have to be specified. Otherwise you have to pass it.
word-based
This function can load the word-based TSV files, not the character based ones.
Parameters
source:string, optionalNone- The key of a known work, see
WORKS. Or the path to the tsv file. raw:boolean, optionalFalse- If True, the lines are split into fields, but no type conversion is done
ocred:string- Whether the tsv file comes from the OCR pipeline. Not needed in case of a known work.
pages:string|int, optionalNone- A specification of zero or more page numbers (see
parseNums()). Only rows belonging to selected pages will be extracted. If None, all pages will be taken.
Returns
tuple-
Two members:
- head: a tuple of field names
- rows: a tuple of data rows, where each row is a tuple of its fields
Expand source code Browse git
def loadTsv(source=None, ocred=None, pages=None, raw=False): """Load a tsv file into memory. The tsv file either comes from a known work or is specified by a path. If it comes from a known work, you only have to pass the key of that work, e.g. `fususa`, or `fususl`. The function needs to know whether the tsv comes out of an OCR process or from the text extraction of a PDF. In case of a known work, this is known and does not have to be specified. Otherwise you have to pass it. !!! caution "word-based" This function can load the word-based TSV files, not the character based ones. Parameters ---------- source: string, optional `None` The key of a known work, see `fusus.works.WORKS`. Or the path to the tsv file. raw: boolean, optional False If True, the lines are split into fields, but no type conversion is done ocred: string Whether the tsv file comes from the OCR pipeline. Not needed in case of a known work. pages: string|int, optional `None` A specification of zero or more page numbers (see `fusus.lib.parseNums`). Only rows belonging to selected pages will be extracted. If None, all pages will be taken. Returns ------- tuple Two members: * head: a tuple of field names * rows: a tuple of data rows, where each row is a tuple of its fields """ (sourceFile, ocred) = getFile(source, ocred) if sourceFile is None: return ((), ()) sep = WORKS[source].get("sep", "\t") pageNums = parseNums(pages) data = [] print(f"Loading TSV data from {unexpanduser(sourceFile)}") with open(sourceFile) as fh: head = tuple(next(fh).rstrip("\n").split(sep)) for line in fh: row = tuple(line.rstrip("\n").split(sep)) if not raw: page = int(row[0]) if pageNums is not None and page not in pages: continue if ocred: row = ( page, int(row[1]), row[2], int(row[3]), *(None if c == "?" else int(c) for c in row[4:8]), int(row[8]), *row[9:11], ) else: row = ( page, *(int(c) for c in row[1:4]), row[4], *(None if c == "?" else int(c) for c in row[5:9]), *row[9:11], ) data.append(row) return (head, tuple(data)) def main()-
Perform tasks.
See
HELP.Expand source code Browse git
def main(): """Perform tasks. See `HELP`. """ args = () if len(sys.argv) == 1 else tuple(sys.argv[1:]) (good, passed) = parseArgs(args) if not good: return good is None kwargs = {k: v for (k, v) in passed.items() if k != "command"} if passed["command"] == "tsv": print("TSV to TF converter for the Fusus project") return makeTsv(**kwargs) elif passed["command"] == "combine": print("TSV combiner of fususa and fususl") return combineTsv(**kwargs) elif passed["command"] == "tf": print(f"TF target version = {passed['versionTf']}") return makeTf(**kwargs) def makeTf(versionTf=None, source=None, ocred=None, pages=None, load=False, loadOnly=False)-
Make Text-Fabric data out of the TSV data of a work.
The work is specified either by the name of a known work (e.g.
fususa,fususl) or by specifying the work directory.The function needs to know whether the tsv comes out of an OCR process or from the text extraction of a PDF.
In case of a known work, this is known and does not have to be specified. Otherwise you have to pass it.
Parameters
versionTf:string- A version number for the TF to be generated, e.g.
0.3. Have a look in the fusus tf subdirectory, and see which version already exists, and then choose a higher version if you do not want to overwrite the existing version. source:string, optionalNone- The key of a known work, see
WORKS. Or else the path to directory of the work. ocred:string- Whether the tsv is made by the OCR pipeline. Not needed in case of a known work.
pages:string|int, optionalNone- A specification of zero or more page numbers (see
parseNums()). Only rows belonging to selected pages will be extracted. If None, all pages will be taken. load:boolean, optionalFalse- If TF generation has succeeded, load the tf files for the first time. This will trigger a one-time precomputation step.
loadOnly:boolean, optionalFalse- Skip TF generation, assume the TF is already in place, and load it. This might trigger a one-time precomputation step.
Returns
nothing- It will run the appripriate pipeline and generate tf in the appropriate locations.
Expand source code Browse git
def makeTf( versionTf=None, source=None, ocred=None, pages=None, load=False, loadOnly=False, ): """Make Text-Fabric data out of the TSV data of a work. The work is specified either by the name of a known work (e.g. `fususa`, `fususl`) or by specifying the work directory. The function needs to know whether the tsv comes out of an OCR process or from the text extraction of a PDF. In case of a known work, this is known and does not have to be specified. Otherwise you have to pass it. Parameters ---------- versionTf: string A version number for the TF to be generated, e.g. `0.3`. Have a look in the fusus tf subdirectory, and see which version already exists, and then choose a higher version if you do not want to overwrite the existing version. source: string, optional `None` The key of a known work, see `fusus.works.WORKS`. Or else the path to directory of the work. ocred: string Whether the tsv is made by the OCR pipeline. Not needed in case of a known work. pages: string|int, optional `None` A specification of zero or more page numbers (see `fusus.lib.parseNums`). Only rows belonging to selected pages will be extracted. If None, all pages will be taken. load: boolean, optional `False` If TF generation has succeeded, load the tf files for the first time. This will trigger a one-time precomputation step. loadOnly: boolean, optional `False` Skip TF generation, assume the TF is already in place, and load it. This might trigger a one-time precomputation step. Returns ------- nothing It will run the appripriate pipeline and generate tf in the appropriate locations. """ doLoad = load or loadOnly doConvert = not loadOnly print("TSV to TF converter for the Fusus project") print(f"TF target version = {versionTf}") good = True print(f"===== SOURCE {source} =====") if doConvert: if not convert(source, ocred, pages, versionTf): good = False if good: if doLoad: dest = getTfDest(source, versionTf) if dest is None: good = False else: loadTf(dest) return good def makeTsv(source=None, ocred=None, pages=None)-
Make TSV data out of the source of a work.
The work is specified either by the name of a known work (e.g.
fususa,fususl) or by specifying the work directory.The function needs to know whether the tsv comes out of an OCR process or from the text extraction of a PDF.
In case of a known work, this is known and does not have to be specified. Otherwise you have to pass it.
Parameters
source:string, optionalNone- The key of a known work, see
WORKS. Or the path to directory of the work. ocred:string- Whether the tsv is made by the OCR pipeline. Not needed in case of a known work.
pages:string|int, optionalNone- A specification of zero or more page numbers (see
parseNums()). Only rows belonging to selected pages will be extracted. If None, all pages will be taken.
Returns
nothing- It will run the appropriate pipeline and generate tsv in the appropriate locations.
Expand source code Browse git
def makeTsv(source=None, ocred=None, pages=None): """Make TSV data out of the source of a work. The work is specified either by the name of a known work (e.g. `fususa`, `fususl`) or by specifying the work directory. The function needs to know whether the tsv comes out of an OCR process or from the text extraction of a PDF. In case of a known work, this is known and does not have to be specified. Otherwise you have to pass it. Parameters ---------- source: string, optional `None` The key of a known work, see `fusus.works.WORKS`. Or the path to directory of the work. ocred: string Whether the tsv is made by the OCR pipeline. Not needed in case of a known work. pages: string|int, optional `None` A specification of zero or more page numbers (see `fusus.lib.parseNums`). Only rows belonging to selected pages will be extracted. If None, all pages will be taken. Returns ------- nothing It will run the appropriate pipeline and generate tsv in the appropriate locations. """ (workDir, ocred) = getWorkDir(source, ocred) if workDir is None: return ocrRep = "with OCR" if ocred else "no OCR" print(f"Making TSV data from {unexpanduser(workDir)} ({ocrRep})") if ocred: B = Book(cd=workDir) B.process(pages=pages) B.exportTsv(pages=pages) else: Lw = Lakhnawi() print("Reading PDF") Lw.getPages(pages) print("\nExporting TSV") Lw.tsvPages(pages) print("Closing") Lw.close() def parseArgs(args)-
Parse arguments from the command line.
Performs sanity checks.
Parameters
args:list- All command line arguments.
The full command is stripped from what
sys.argvyields.
Returns
passed:dict- The interpreted values of the command line arguments, which will be passed on to the rest of program.
Expand source code Browse git
def parseArgs(args): """Parse arguments from the command line. Performs sanity checks. Parameters ---------- args: list All command line arguments. The full command is stripped from what `sys.argv` yields. Returns ------- passed: dict The interpreted values of the command line arguments, which will be passed on to the rest of program. """ passed = dict( command=None, source=None, ocred=None, pages=None, load=None, loadOnly=None, versionTf=None, ) good = True NUMS = re.compile(r"^[0-9][0-9,-]*$") def setArg(name, value): nonlocal good if passed[name] is None: passed[name] = value else: print(f"Repeated: `{value}` for {name}") good = False for arg in args: if arg in {"tf", "tsv", "combine"}: setArg("command", arg) elif arg == "load": setArg("load", True) elif arg == "loadonly": setArg("loadOnly", True) elif arg == "ocr": setArg("ocred", True) elif arg == "noocr": setArg("ocred", False) elif "." in arg: setArg("versionTf", arg) elif NUMS.match(arg): setArg("pages", arg) elif arg == "--help": print(HELP) good = None else: setArg("source", arg) if good: if passed["command"] is None: print("No command specified (tf or tsv or combine)") good = False if passed["source"] is None: if passed["command"] == "combine": print("No destination specfified (fusus)") else: print( "No source specified " "(fususl, fususa, commentary_name, directory_path)" ) good = False if passed["command"] == "combine": if passed["versionTf"] is None: print("No TSV version specified (e.g. 0.3)") good = False if passed["command"] == "tf": if passed["versionTf"] is None: print("No TF version specified (e.g. 0.3)") good = False if passed["load"] is None: passed["load"] = False if passed["loadOnly"] is None: passed["loadOnly"] = False else: for name in ("load", "loadOnly"): if passed[name] is not None: print(f"Illegal argument `{passed[name]}` for {name}") good = False del passed[name] print(f"{good=} {passed=}") return (good, passed)